How Lomb Works
1. Read whatever you want
Choose a text or upload your own.

2. Assisted Reading
Clicking on a sentence reveals its translation. Highlighting a word shows its definition and saves it for future review.

3. Tracking powers efficient revision.
Scrolling is also tracked and used to filter out words which are known.

4. Learn with videos too
Lomb's dual language subtitle player is ideal for working with videos. The interactions are also tracked and used for memory trace estimation. All new words are added to the revision list automatically.
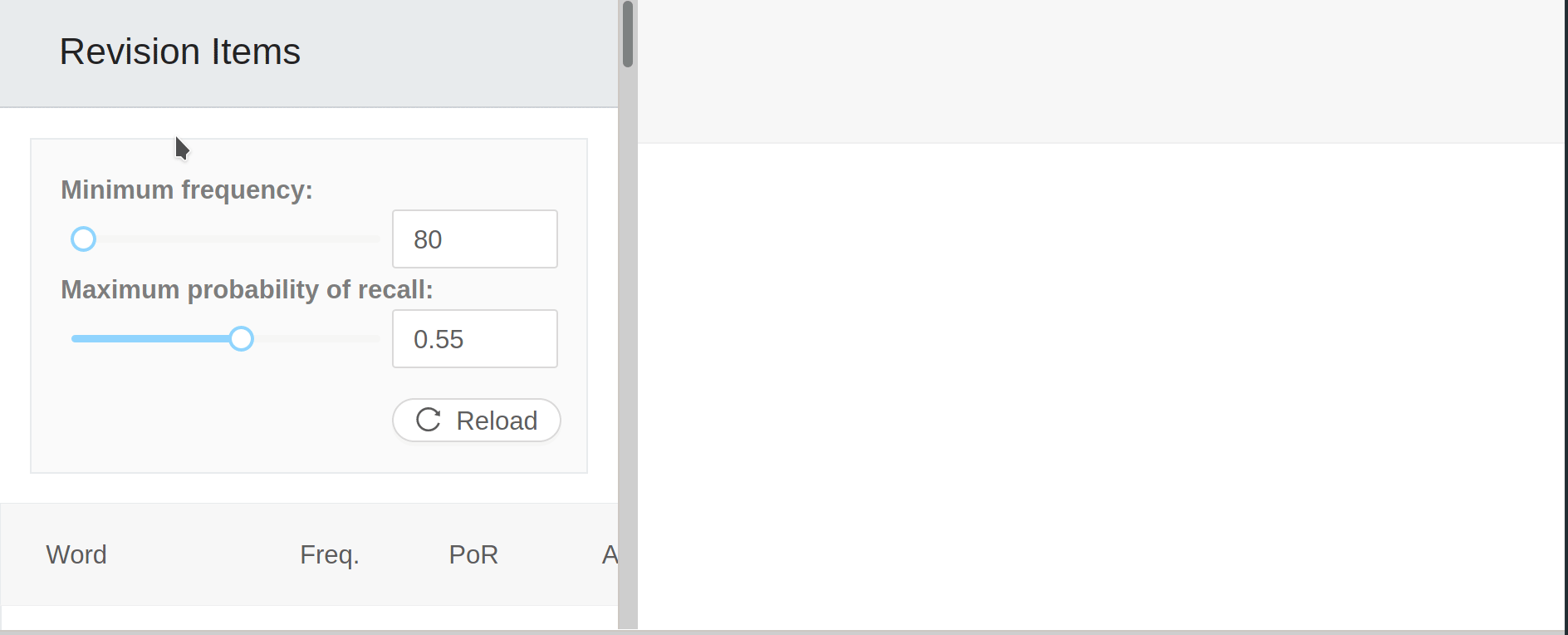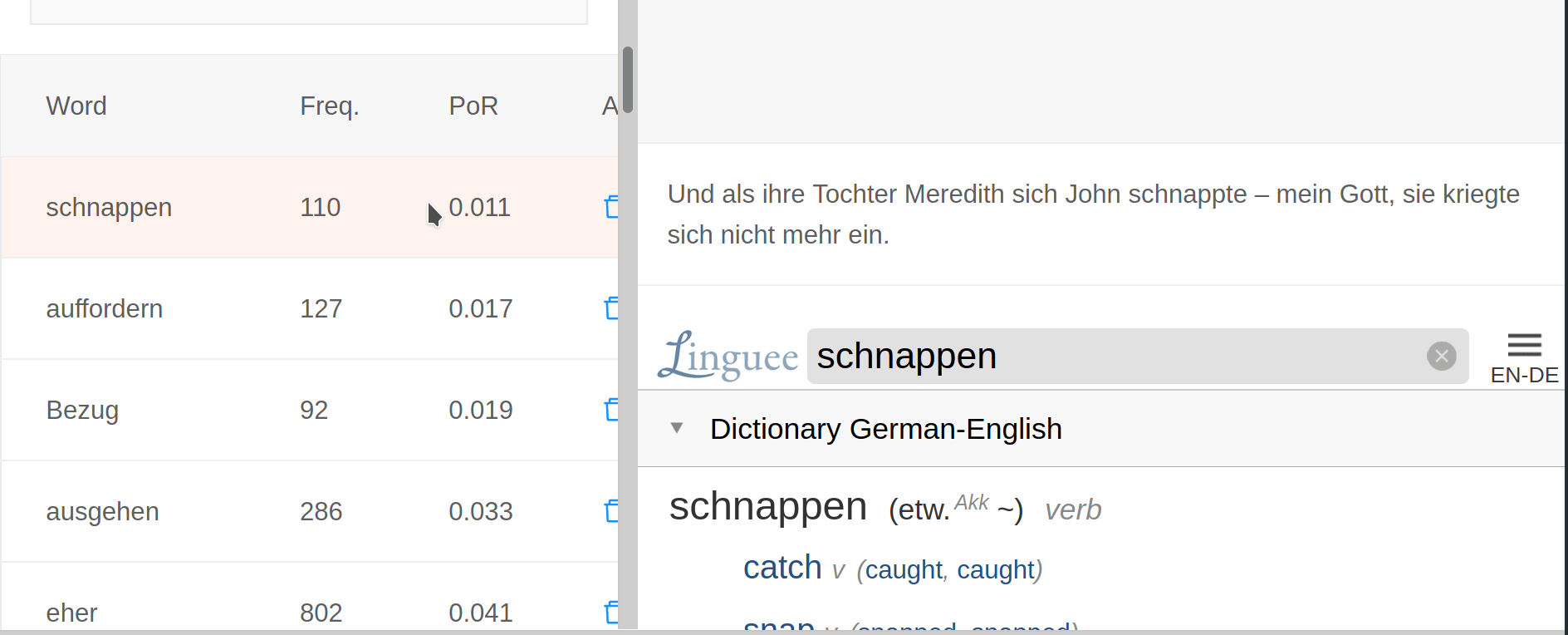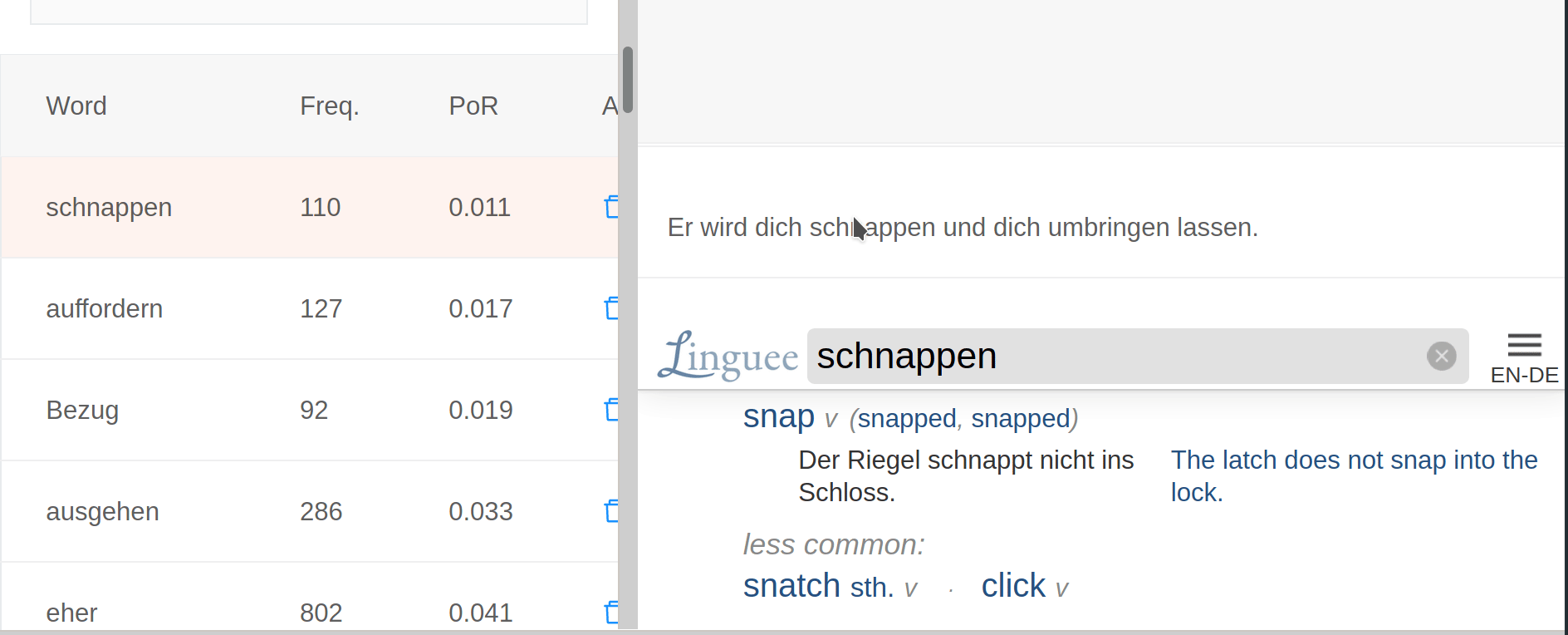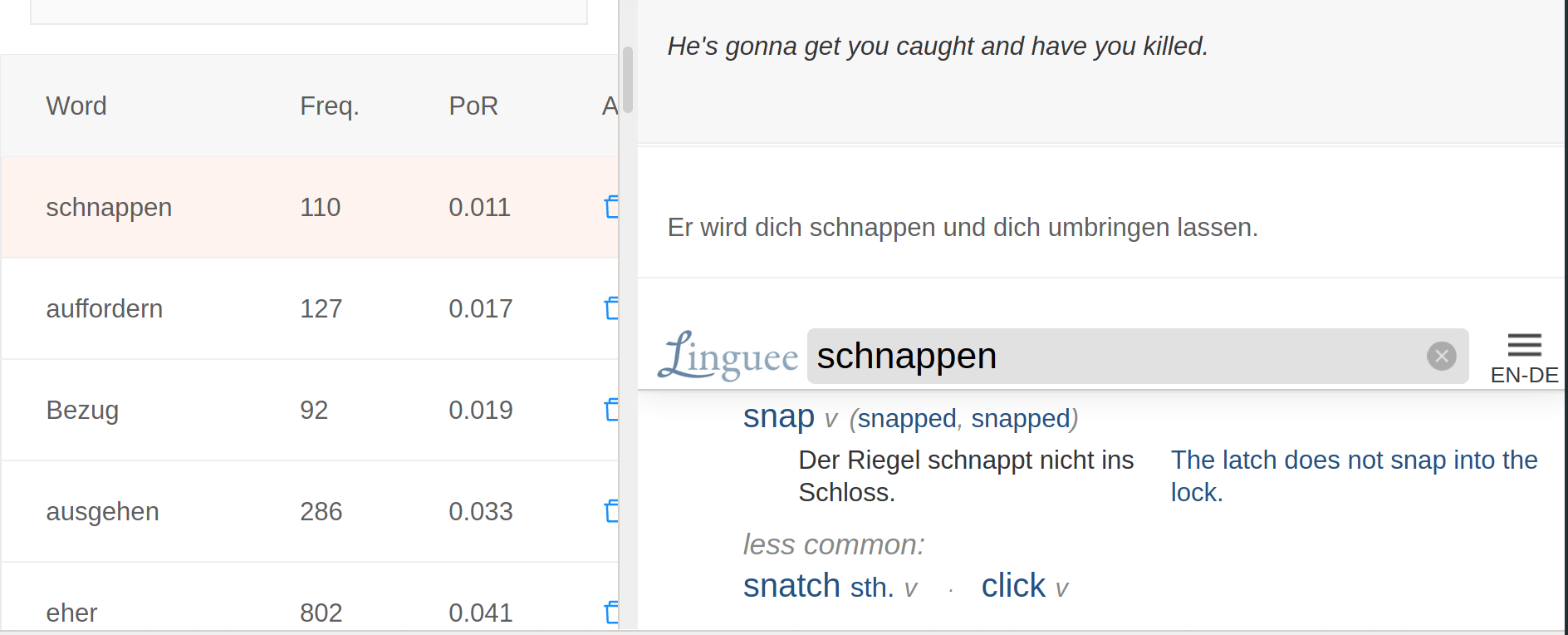
5. Perfect revision
The most technologically impressive feature of Lomb is its revision panel. All the data gathered from elsewhere in the platform is used here to craft perfectly-targeted revision sessions. Contrary to SRS apps, the revision panel is designed to allow users to customize the revision sessions according to how much time they have available.
The Problem: Drill and Kill!
Before Lomb, there were simply no apps which could leverage the data generated by complex, immersive tasks. Apps like Duolingo are drill-based repetition nightmares, whereas reading aids like ReadLang or LingQ do not offer users the possibility of revising vocabulary in an efficient way.
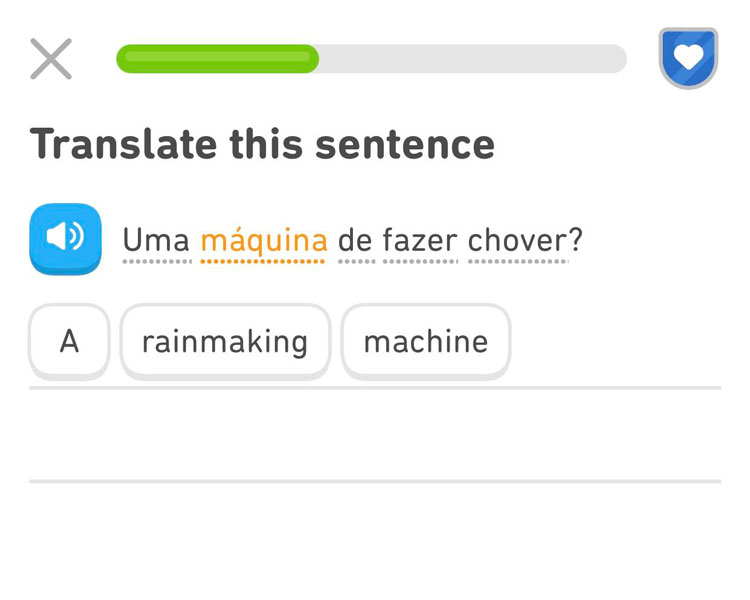
Translating sentences Duolingo-style is tedious and of little value for mastering a language.
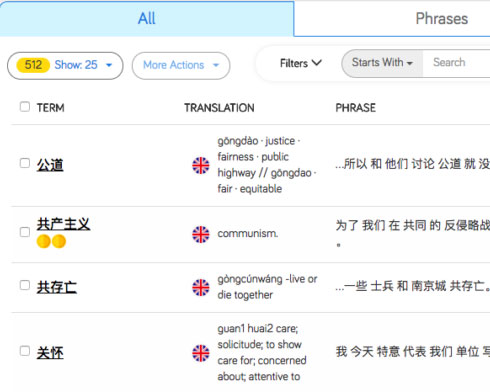
The revision list on apps like LingQ quickly becomes unmanageable and is of no real use.
The Development of Lomb
0. Conception
Lomb originated from a series of scripts I wrote when I started learning German.
One of these scripts would generate the word frequency list from a text or collection of texts. All sentences in the text were lemmatized using Python’s NLP libraries, and then the frequency of each lemma was tallied. The script just dumped this list as a raw text file and I studied from there. Soon I extended the script to accept a blacklist of words to be filtered out. Since this blacklist was just the original list with the unknown words deleted, I originally studied in vim. I would go line by line deleting unknown words until I ran out of patience and deleted the rest of the document. Soon I had a reasonably large blacklist, but still the process was very inefficient.
Another script I wrote around this time was a parallel text reader. This script would use Google Translate to translate each sentence of a text and output an html file with the text in both languages (the translated sentence could be revealed on clicking). Soon, I added an iframe to the side to display definitions on word highlight events.
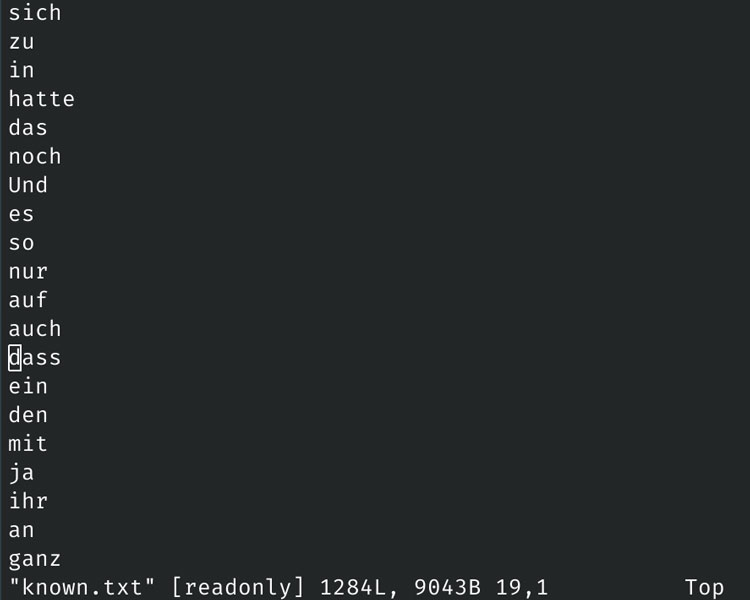
In the early days, I would have to edit word lists using vim to generate the blacklist.
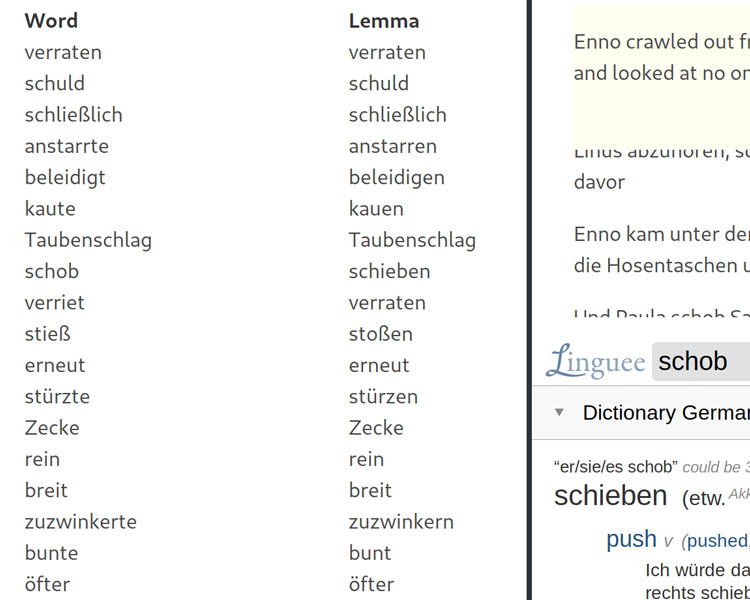
One of the early statically generated word frequency lists, an html file with all the examples and an iframe with an online dictionary.
1. Research
The more I worked with my scripts, the more excited I became at the level of control I had over my learning process, and many possibilities and ideas started to take form in my head:
- My initial script calculated frequencies for individual texts, or a selection of texts. However, this approach biases the frequencies towards words which appear frequently in those texts, which might in fact not be all that frequent in the language. In general, that is not desirable. A unified platform with a repository of texts could solve this problem. Additionally, the whole repository could then be reverse-indexed by words, allowing finding frequencies and examples much faster and therefore enabling many features (e.g what happens when new texts are added).
- Recall that at this point I was still having to work on a blacklist by hand. However the clicking and scrolling involved in reading and revising could be tracked and used to determine which words were already known, and which were unknown or likely to be forgotten soon.
I had recently read Eric Evans’ Domain-Driven Design book, which had a strong impact in my way of approaching software development. One of the main ideas of the book is that software development can be seen as a way to develop an ubiquitous language, that is, a way to capture expert knowledge with words in a very precise manner, informing the naming conventions in the software. It was hence imperative that I did research because I had neither the expert knowledge nor the vocabulary to describe my problem well enough.
I spent a few weeks reading all sorts of related research: memory retention, computer-assisted language-learning, SRS and machine learning algorithms for language learning… Some highlights, in no particular order:
- 100 Years of Forgetting. An extensive survey of memory trace datasets dating back all the way to the 19th century. It shows that several two-degree-of-freedom functions can fit the dataset very well (around 90% explained accuracy). Power-law and logarithmic functional forms perform very well, whereas the exponential decay model used or implied by many popular SRS algorithms performs really badly.
- Wickelgren's function (original paper, simplified version). A modified power law function that has the wonderful property of being defined for all non-negative reals.
- An unbiased assessment of the effectiveness of SRS, which finds that most users surveyed were so bored that they didn't even use the app (Anki, in this case) for the whole 12 weeks the study lasted.
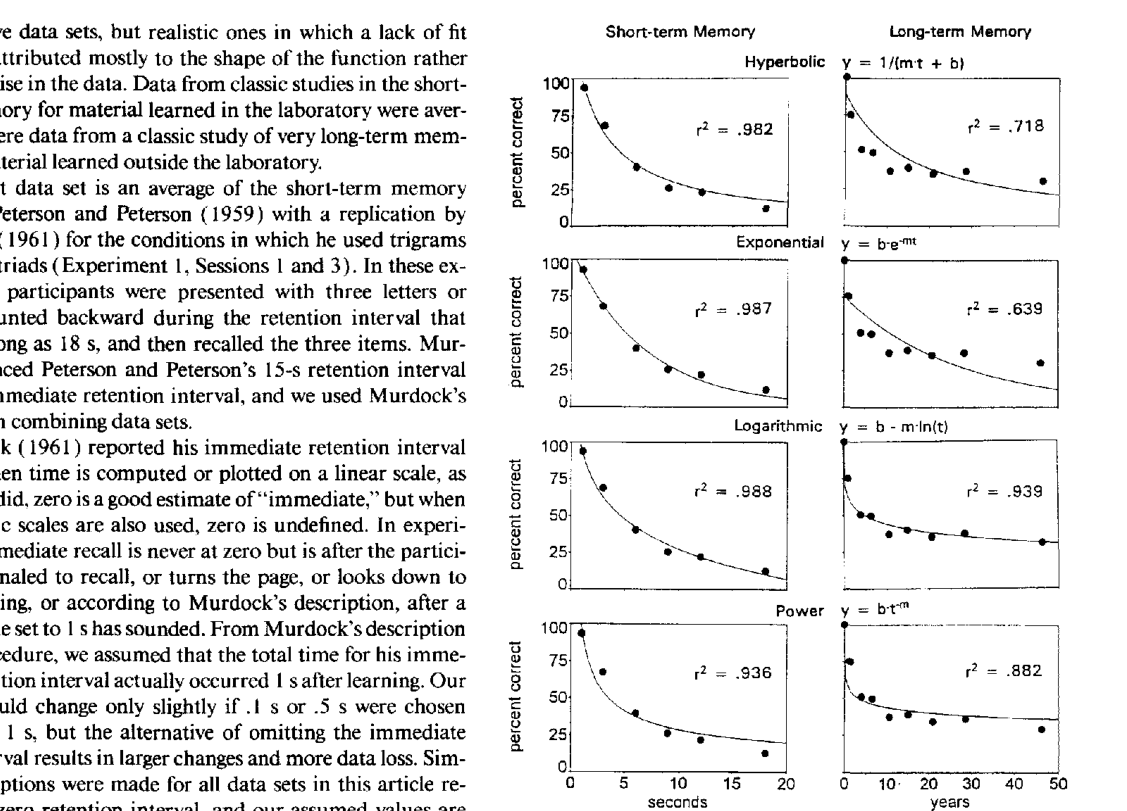
The 2-degree-of-freedom curves in 100 Years of Forgetting were quite important in the development of the MTR procedure.
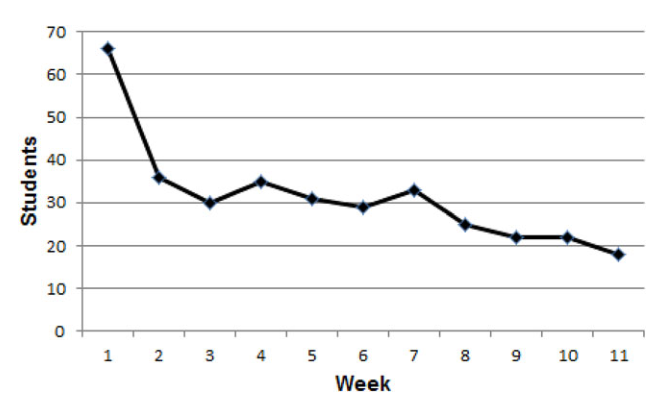
The attrition rate of SRS apps like Anki is spectacularly high.
2. Design
With a better idea of what the field was like, I set out to outline my requirements for the project, and then to design the whole system. My first challenge was thinking about the domain: what processes were going to be described by the system and how should the be defined? Additionally, how should the domain be split into bounded contexts? At the time it was not obvious how to do this, but I settled into users, tracking, library and vocabulary. Each bounded context would have a domain module where all of the domain ideas were described in a high-level, declarative way, and expose some entities and services which the application layer could then work with.
As it turned out, this architecture was quite a good fit for the problem, but not perfect. The two main flaws of this architecture are:
- The users bounded context would have been simpler if it had just been some controllers and repositories. It didn't really need a domain module.
- The library and vocabulary contexts should be merged into a larger texts context. These two contexts are essentially the core of the application: they provide entities for many use cases that have to go around the partition somehow, and it is reasonable to think that will be the case in the future as well. Although merging implies a more complex bounded context, the alternative implies hidden dependencies and APIs which are interdependent (i.e. protocols), and therefore hard to work with.
The reason why I was satisfied with the architecture, though, was because those flaws were easy to correct. The first flaw was minor: just a slightly overengineered context, but still simple enough to be maintainable and extendable. The second flaw was important: the split between vocabulary and library made developing features that required entities from both contexts cumbersome. Thankfully, merging both contexts was done early enough to not be too time-consuming.
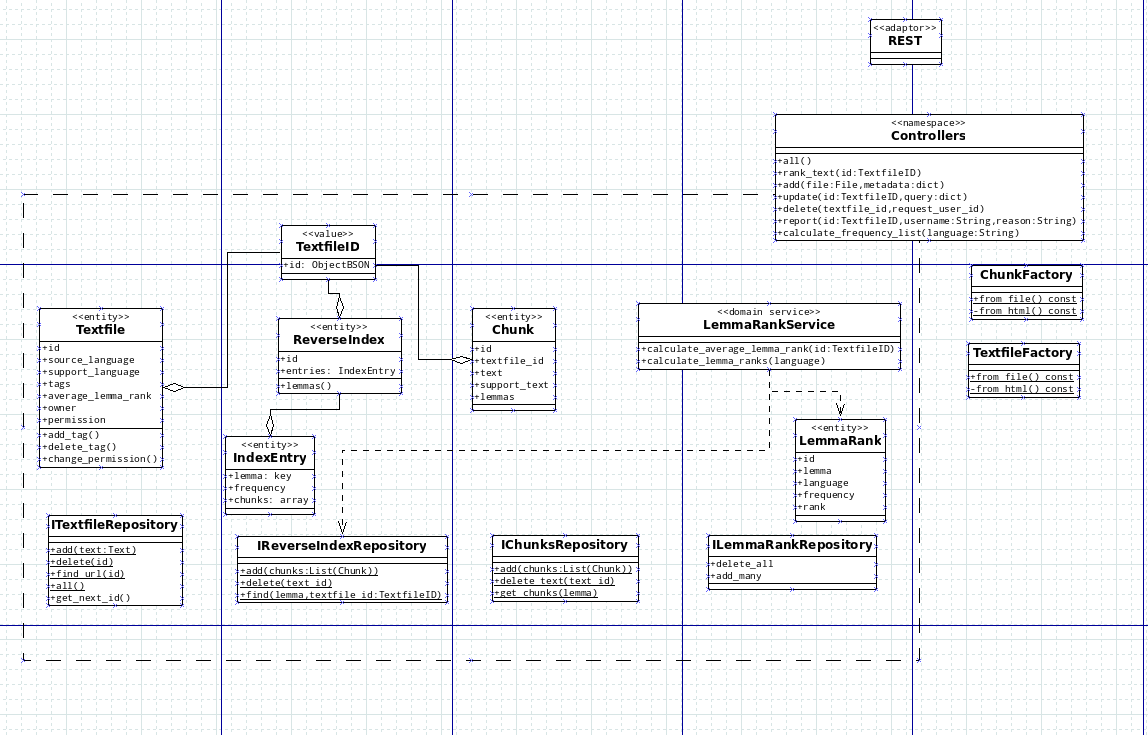
An early UML sketch of the Library bounded context before it was merged with the Vocabulary bounded context.